|
I am Chin-Lun (Allen) Fu, and I am a second-year MSCS student at UCLA. My researh focused on multi-modal learning and instrcution fine-tuning. In the past, I received a B.S. degree from the Electrical Engineering Department at National Taiwan University, where my research focuses on parameter-efficient-tuning with Large Language Models (LLMs) in different domains, spanning from Natural Language Processing (NLP), Speech, and Computer Vision (CV). At National Taiwan University, I was fortunate to work with Prof. Hung-yi Lee on efficient-tuning in NLP and Speech tasks, and with Prof. Yu-Chiang Frank Wang on domain generalized problem. Email / CV / Google Scholar / Github / LinkedIn |

|
|
|

[2024.06 - 2024.09] AI/ML Associate |
[2022.04 - 2022.11] Research Intern |
|
|
|
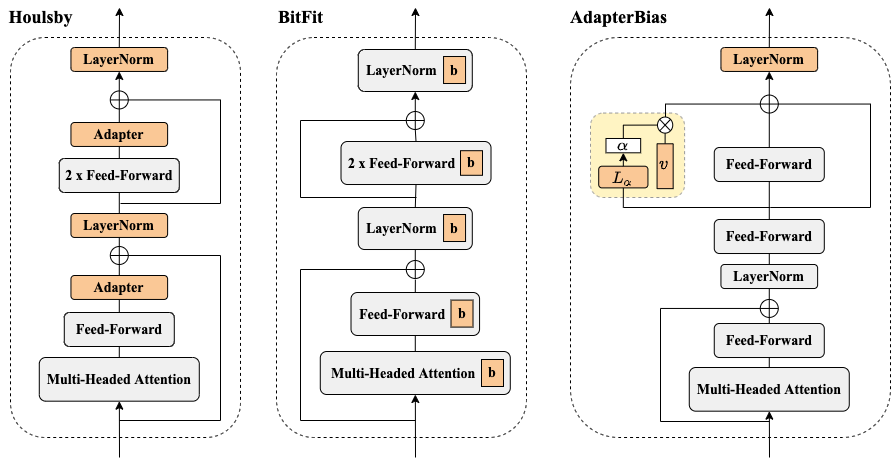
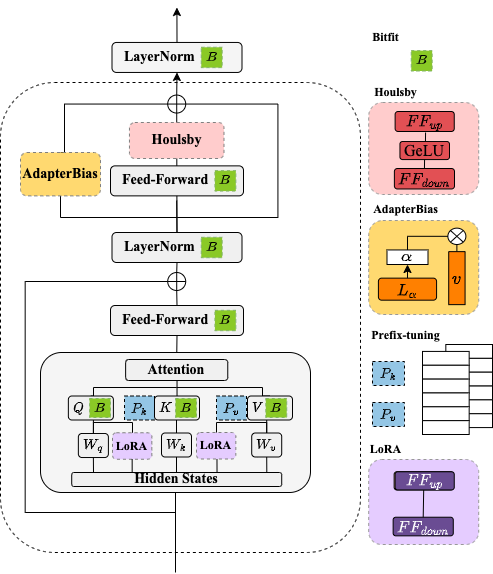
Chin-Lun Fu*, Zih-Ching Chen*, Yun-Ru Lee, Hung-yi Lee Findings-NAACL, 2022 arXiv / code In this work, we present AdapterBias. By adding token-dependent representation shifts to the PLM, AdapterBias shows competitive results even though it uses far fewer parameters than the existing methods. |
|
Zih-Ching Chen*, Chin-Lun Fu*, Chih-Ying Liu, Shang-Wen (Daniel) Li, Hung-yi Lee SLT, 2022 arXiv In this study, we aim to explore efficient tuning methods for speech self-supervised learning. We show that the performance parity can be achieved with over 90% parameter reduction, and discussed the pros and cons of efficient tuning techniques. This is the first comprehensive investigation of various adapter types across speech tasks. |
|
Zih-Ching Chen*, Lin-Hsi Tsao*, Chin-Lun Fu*, Shang-Fu Chen, Yu-Chiang Frank Wang ICME, 2022 arXiv Based on the idea of representation disentanglement, we present a network architecture that is able to extract facial liveness, content, and domain features. |
|
Source code credit to Dr. Jon Barron |